IMProv - Compute Canada Cedar Deployment Tutorial
This tutorial presents the step by step instructions to gather the data files and driver scripts needed to perform a MPI based IMP modeling job run. We demonstrate these steps using the PRC2 example project and explain how this was prepared using MassSpecStudio. The instructions cover running the job on the Compute Canada: Cedar cluster.
PRC2 example project (download):
The data folder contains various artifacts used to inform the integrative modeling. The imp_model folder contains the driver python script and example yaml configuration for running the IMP modeling job.
Fast Track:
Login to Cedar on Compute Canada and run these scripts in your user account and see Installing section and follow the steps to run each of the setup scripts in turn.
Getting Started:
These instructions will get you a copy of the example project up and running for testing purposes.
-
How to setup new instance with python (3.x) and imp packages, together with sample
project for PRC2.
- initial run for modeling 200 frames ( approx. run duration is 10min ).
-
How to deploy the project on a live system for a short run.
- runbook for steps to setup software and data/driver scripts.
- playbook for troubleshooting issues.
Cedar job run:
- Links to Cedar preparation docs, account setup, login and run setup scripts.
- Cedar HPC intro, on Compute Canada.
- Cedar login steps. On Windows, there are 2 options: MobaXTerm and PuTTY.
- See Installing section.
Prerequisites
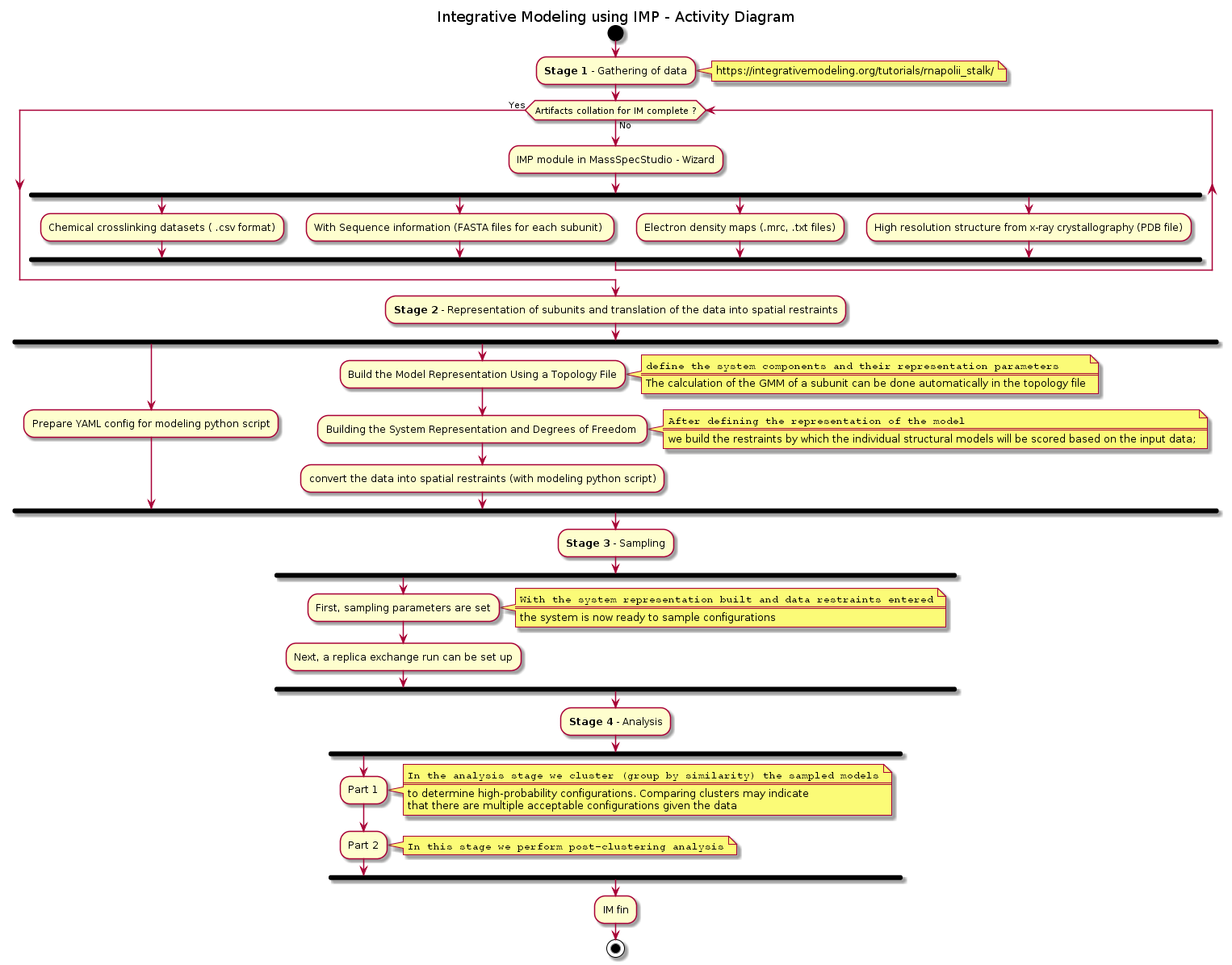
The PRC2 sample project was prepared using the MassSpecStudio application. The IMP job driver script runs with python 3.x and has a dependency on the Python Modeling Interface (PMI)
The initial software installation of python with Anaconda and python packages for imp are included in the setup script. The individual steps are highlighted once again, hereafter.
#initial setup for PMI using anaconda
Anaconda3\Library\bin\conda config --add channels salilab
Anaconda3\Library\bin\conda install imp scikit-learn matplotlib
#https://integrativemodeling.org/tutorials/rnapolii_stalk/
Anaconda3\Library\bin\conda install numpy scipy
#bring up Anaconda Prompt and run : activate base
#you can see envs available with: conda info --envs
#for example: this shows us that base is c:\apps\Anaconda3
Performance Expectations: On a 16cpu instance we have observed up to 50 frames per minute throughput, although 30 frames per minute is typical. We expect 20000 frames to complete in 10 hours ( based on PRC2 example ).
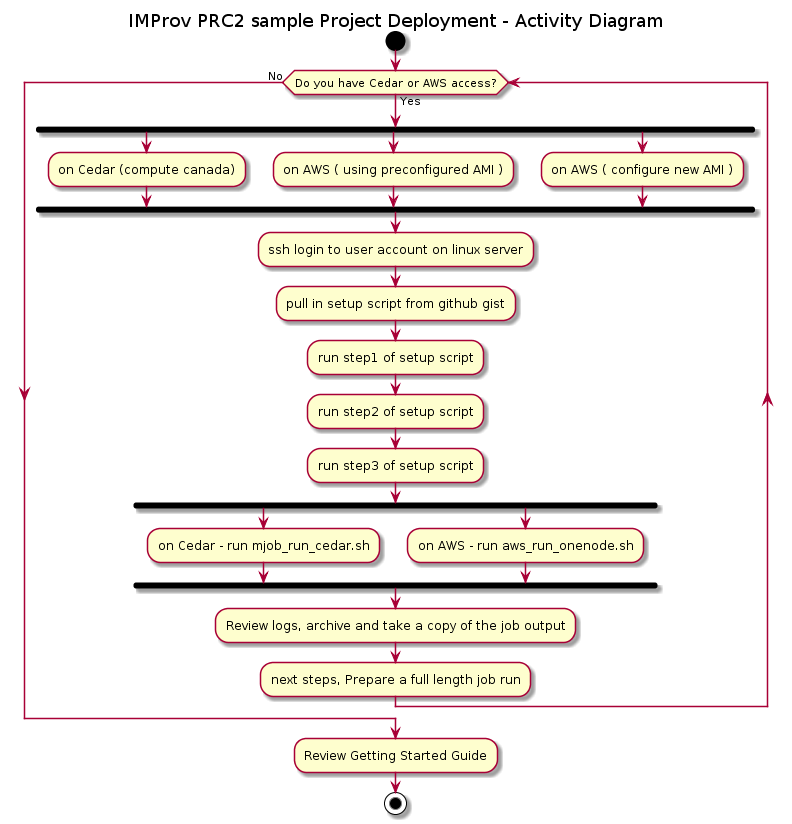
Installing
The readme_setup_cedar.txt is a good place to start. This explains how to setup the example project on Compute Canada's Cedar cluster.
Taken from the readme_setup_cedar.txt:
#### get the setup script from github gist and review before running:
~~~
curl -LOk https://gist.githubusercontent.com/pellst/4853822ea5ca74785af61d0ad39cf84d/raw/uoc_mss_prep_step1.sh
chmod 755 uoc_mss_prep_step1.sh
~~~
#### run the script uoc_mss_prep_step1.sh in order to get the sample folders and scripts setup
~~~
./uoc_mss_prep_step1.sh
~~~
#### in the folder /scratch/$USER/imp/imp_msstudio_init-master/mss_out/imp_model, the following shell scripts are now available
~~~
> > > uoc_mss_prep_step1.sh
> > > uoc_mss_prep_step2.sh
> > > uoc_mss_prep_step3.sh
~~~
#### we can continue on to step2 to setup anaconda
./uoc_mss_prep_step2.sh
conda --version
python --version
#### once anaconda has been setup we can bring in the imp module and others needed for the job run
./uoc_mss_prep_step3.sh
#### the next step is to review the following:
#### located in /scratch/$USER/imp/imp_msstudio_init-master/mss_out/imp_model
ConfigImp.yaml
mjob_run_cedar.sh
Amend the sampling_frame in ConfigImp.yaml:
sampling_frame: 100
- The cores is used for the ntasks-per-node=x where x=16 is a good starting point
- performance expectations are that with a single node and 1 cpu per task and 16 tasks per node we can run 20000 sampling_frame in 9 hours.
Amend the slurm script settings in mjob_run_cedar.sh:
#!/bin/bash
# example slurm job script setup to run on for example Cedar ( replace sponsername appropriate for your account)
#SBATCH --job-name=SLURM_imp
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=16
#SBATCH --cpus-per-task=1
#SBATCH --mem=32G
#SBATCH --time=0-01:00:00
#SBATCH --account=sponsername
In order to run the job we call this and give a unit number to be used for naming the folder that is setup eg: 12 here.
chmod 755 mjob_run_cedar.sh
./mjob_run_cedar.sh 12
#monitor the job run
squeue -u $USER
Once the job has finished, look in the imp_model_12 folder and inspect the logs
tail -100 prep_hyperp_imp_v2ux.log
#do the same for the slurm-nnnnn.out
A successful run will include the output folders from the job. Copy the entire imp_model_12 to local machine ( optionally tar the folder in order to archive).
In order to run multiple jobs in parallel. From the imp_model folder amend the configuration as needed and call mjob_run_cedar.sh nn once again.
The wrapper script mjob_run_cedar.sh essentially performs a slurm job scheduler call to launch: runs python prep_hyperp_imp_v2ux.py and this in turn runs the prep_hyperp_imp_v2ux.py driver script. The configuration of the driver script is accomplished with the ConfigImp.yaml There are assumptions that have been made and while a basic modeling run has been anticipated. The prep_hyperp_imp_v2ux.py script can be customised further in order to fit the specific modeling scenario.
finished
Compute canada will purge files older than 60days in the /scratch/$USER area. Purge and re-deploy as required.
Deployment
Additional notes about how to deploy this on a live system.
- Cedar ( Compute Canada cluster ) The installing section, above, provides the steps to follow in order to prepare your user account on Cedar with the required software together with the PRC2 sample project. We have selected Cedar for our example. There are other clusters on Compute Canada that are available, such as Graham.
- alternatively: see the readme_setup_cedar.txt included in the /scratch/$USER/imp/imp_msstudio_init-master/mss_out/imp_model folder setup by the script uoc_mss_prep_step1.sh.